
Advanced Sprint Metrics Are for Everyone
Good processes can save you time, regardless of your team’s size or maturity.

I often see new teams “cowboy coding” – that is, developing software without any semblance of a planning process.
Sometimes people do this because they don’t know any better and lack guidance. Other times, however, it’s a deliberate choice – one which I believe is misguided.
Those who adopt sprint metrics often stop at out-of-the-box reports without thinking about their blind spots. In extreme cases, the metrics can look great while the team is utterly failing to complete meaningful work.
Advanced sprint metrics can help teams of any size do more with less by exposing common sources of inefficiency and drive continuous improvement during retrospectives.
In this article, we look at why that is, what advanced metrics real teams use, and how to measure them.
Bad arguments against planning
“Planning is for managers”
Some people believe that agile processes are only for larger, more mature companies. This is a common misunderstanding about the purpose of planning. Sprint processes aren’t there to benefit management; they are mainly there to help teams meet their goals.
By not planning, you might upset your manager (if you have one), but you’re really just hurting yourself.
“I’ve got too many bigger problems to worry about planning”
Another common argument I hear from new teams is that there are so many larger risks – like customers not wanting the product or not having a viable way to sell it – that it’s not worth the effort to worry about predictable delivery.
While it’s true that other things are more likely to kill a start-up, this is a misguided and fatalistic attitude. By this reasoning, does your business not pay taxes or follow employment laws? I hope not, because you’re going to be in for a world of hurt if you do have initial success.
When there’s a risk of building the wrong thing, you should still try to do it as efficiently as possible.
“Planning takes away my autonomy”
One side-effect of good planning is that it can make implementation boring. Instead of solving problems during implementation, engineers are forced to think about and solve those problems up front.
Sometimes engineers aren’t happy about this and claim a loss of autonomy, especially if they are more senior.
If you feel this way, you need to shift your mindset. Good planning actually empowers senior engineers by letting them focus on hard problems during the planning stage and allowing them to delegate tasks to less-skilled engineers that otherwise would have been too difficult.
If you’re doing it right, good sprint processes should give everyone more autonomy by organizing work into tasks of the right difficulty level for each person.
“Up-front estimation is impossible, and doing it locks in bad plans”
Estimation is a perennial challenge in software engineering. The book Shape Up by the creators of Basecamp takes the position that estimation is impossible and argues that you should instead try to just get as much done as you can within a 2- or 6-week window.
The argument is that you know the least about what to build at the start of a project, so trying to plan and lock in the design up front will lead to worse results.
There is some truth to the premise, but I disagree with the conclusion that estimating and planning work in sprints is not helpful.
It all comes down to a matter of scale. Of course it’s bad to rigidly define the scope of a 6-week project and stick to it regardless of what happens. However, it is beneficial to define and estimate small tasks like “Add this button to the UI.”
Just because there is ambiguity in the project scope doesn’t mean you should have ambiguity in the task scope.
In a good sprint process with short sprints, you estimate well-defined tasks while still having flexibility at the project level by regularly adjusting the scope of tasks in each sprint iteration.
Aren’t sprint reports good enough?
If your team is new, you might think that advanced sprint metrics aren’t for you, and that reports in Jira (or another tool) are good enough to start.
While default reports will uncover many issues and are better than nothing, you can still get value out of advanced metrics even if you haven’t mastered the basics.
It all comes down to incremental visibility. Default reports will show you problems of type A, B, and C, while advanced metrics highlight issues of type D, E, and F. New teams will still want to address low-hanging fruit first, but some of that low-hanging fruit may be in those later D, E, and F categories, so looking at advanced metrics from the beginning can give you a head start.
Which advanced sprint metrics do real teams use?
Basic sprint reports will tell you things like the number of story points committed at the start, number completed, and how many were added or removed from the sprint. These are good high-level metrics that can uncover bigger problems with estimation and interruptions, but there’s a lot they don’t catch.
Working on minware, I've been fortunate to see what real teams of all shapes and sizes do to improve their efficiency.
One thing that’s surprised me is that some small companies (<10 developers) use almost all of these metrics and are extremely efficient even though calculating the metrics can be a lot of work. On the flip side, some teams in high-profile public companies are quite inefficient and only look at basic sprint reports without digging deeper.
The overall trend I see is that small teams who do these things well have a big competitive advantage and are running circles around the competition.
This section introduces advanced metrics in use by real teams, talks about why they are important, and describes how to measure them.
Bug load (BL)
Why it’s important
One sure-fire way to juice your sprint metrics is skip testing and launch whatever you have at the end of the sprint. All the bugs you create will then show up as new tickets with more story points in the next sprint, so you can always meet your commitment!
I have seen cases where people throw such garbage over the finish line that they regularly deleted and rewrote 80% of their code each sprint.
You can mitigate this anti-pattern by tracking how much time you spend each sprint fixing old code vs. actually completing new work. The bug load should ideally be low and consistent.
How to measure it
This metric is straightforward to compute with an exported spreadsheet. If you use Jira, you can download a CSV of all ticket fields right from the issue search screen to get all of the tickets in a particular sprint. Once you have tickets along with their story point estimates in a spreadsheet, you can make a pivot table by issue type to see how much effort went into fixing existing code vs. completing new tasks.
Additionally, you should look at each of the non-bug tasks to make sure that they aren’t bugs in disguise. If a non-bug task is primarily related to fixing existing code, you can reclassify it as a bug in the spreadsheet before making the pivot table to get a true read on bug load.
In minware, you can see the inverse of this metric – non-bug load – in the Bug Management report. This metric further looks at dev time spent on each of the bug tickets so that it isn’t biased by inaccurate story point estimates. It further looks at bug fix vs. find rate to guard against the scenario of shipping bad code and then not even fixing it in a later sprint.
Large task sizes (LTS)
Why it’s important
One limitation of basic sprint metrics is that they focus on total points completed without emphasizing the size of each task.
This enables a common anti-pattern where people represent all their work in a few large tickets. This defeats the purpose of sprint planning and effectively means that there is no plan.
I have literally seen people put all their work in a single 20-point ticket and mark that done at the end of each sprint. They always completed exactly 100% of their sprint commitment!
It’s important to keep an eye on this by looking at how much work goes into tickets spanning more than a few days.
How to measure it
Fortunately, large task sizes are easy to see using data from Jira. Starting with tickets exported from a sprint, you can create a pivot table for each person to show the number of tickets by story point estimate.
Once you have this information, it’s important to look at both large tasks that had a large estimate, which you can compute by just looking at the story point field and filtering by value (e.g., > 5) to make sure larger tasks are rare and could not have been easily broken down when they occur.
However, you will also want to make sure there aren’t any large tasks with small estimates. To identify these, you should look at cases where a person’s total completed points were unusually low, and then click into each of the tickets with small estimates to see when each one started and stopped to identify the underestimated task.
minware’s Work Batch Sizes report rolls up all this information for you. It uses the amount of dev time spent on each task rather than the point estimate so that it can identify large tasks regardless of their original estimate.
Under-the-radar (UTR) work
Why it’s important
Jira can’t know what it doesn’t see. If people do work that isn’t tied to a ticket, then it won’t show up in a sprint report.
The first question you should ask whenever you don’t meet your sprint commitment is: were people actually working on the sprint?
If unmonitored, under-the-radar work can have a major impact on sprint completion. In extreme cases, it can hide the fact that people are really cowboy coding and the sprint metrics are a lie.
How to measure it
This one can be tricky to do on your own because the work is inherently not in Jira (or whatever project management system you’re using).
There are a few sources of information outside of Jira that you can look at to manually compute how many hours a week are lost to under-the-radar work:
Calendars - Look at each person’s calendar on the team, adding up how much time they spend on meetings not related to sprint work, and also factoring in disruption time before/after and between closely-scheduled meetings where it’s difficult to do focused work.
Main branch commits - For each of the repositories where your team works, look at how many direct commits there are on the main branch (that is, commits not tied to a pull request) and whether those commits are related to a sprint task, or are related to other overhead.
Unlinked pull requests and branches - Most teams have a practice of including the ticket key (e.g., DEV-123) in the branch name or pull request title so that you can tell which ticket it’s associated with. If you review the recently active branches and pull requests in each of your repositories, you can look for those that are unticketed and see approximately how much time was spent on them.
Work on off-sprint tickets - Here you can look at both pull request activity and query Jira for recently updated tickets that are assigned to people on the sprint team, but not in a sprint. This will give you a sense of how much time went into non-sprint tickets.
Ask people - It can be hard to remember how much time you spent on under-the-radar work and people can sometimes have an incentive to be dishonest (e.g., if their manager said not to work on something that they think is important), but if you complete the previous steps and have a list of those activities, you’re more likely to get an accurate estimate from people of how much time they lost to under-the-radar work.
This can be a lot of effort to compile manually for every single person and sprint retrospective, so what you might want to do is sample it from time to time (e.g., every four sprints) to see how big of an issue it is, or if there are particular areas that would benefit from closer monitoring.
If you want to see these metrics in minware, you can look at the Code/Ticket Traceability report and the On-Sprint Work metric in the Sprint Best Practices report.
Work in progress (WIP)
Why it’s important
Whether you complete each task one-at-a-time or start everything on day one and finish it at the end, the metrics will look the same.
However, the reality is that working on a lot of things at once will cause them all to take longer, but it will be less obvious why. The individual task estimates may all be correct, but you can lose a substantial amount of time to context switching.
If the team makes a habit of high work-in-progress, its capacity may just look lower than its true potential, which you will never know from looking at sprint reports.
While normally reserved for a kanban process rather than sprints, looking at your average work-in-progress can identify lost capacity due to context switching.
How to measure it
This one is a bit trickier to calculate yourself in a spreadsheet. To do it, you have to manually add the time when each ticket started in a new column. Once you’ve done that, you can subtract the start from the resolved time to get the in-progress duration.
Finally, you can add up the in-progress durations for each person’s tickets in a pivot table and divide that by the length of the sprint to get the total average work in progress for each person and for the team.
You can find the work-in-progress metric in minware’s Kanban Essentials report.
Bug SLA resolution (BSLAR)
Why it’s important
Teams that support production software inevitably encounter high-priority bugs, which can disrupt sprint plans.
While sprint plans are important, they’re not as important as customers being able to use existing software.
Looking at whether bugs are resolved within a predetermined SLA based on their priority helps ensure that there is no incentive to neglect important but disruptive work for the sake of improving sprint metrics.
How to measure it
To compute bug SLA resolution, you can use a spreadsheet exported from Jira. You can get both “Created” and “Resolved” as exported fields.
Then, you can sort the tickets by priority level and compare the time from creation to close to a predetermined SLA duration to flag bugs that exceed the SLA.
minware’s Uptime Dashboard report shows time from creation to close for bugs of a particular priority level at the bottom. You can copy this for each priority level with a different SLA to get a count of the bugs above and below the threshold.
As its name implies, this report also shows your total uptime and downtime for highest-priority bugs, which is probably a better metric than bug SLA resolution for most teams because it accounts for the number of high-priority bugs too. This is just hard to calculate on your own without a system like minware, so you might prefer the simpler bug SLA resolution.
Capacity utilization rate (CUR)
Why it’s important
The easiest way to always meet your commitment is to undercommit.
Because sprints metrics often use story points, it’s not always obvious when the commitment is far below the team’s capacity.
The capacity utilization rate looks at how much time people actually spent on sprint tasks.
Note that having some slack time is good for a well-functioning team. There’s an entire book about it, which I highly recommend.
The purpose of this metric is not to ensure that everyone is working at 100% capacity and burning out, but instead for managers to ensure that they are looking at other metrics fairly between teams and that they themselves are not inadvertently incentivizing people to significantly undercommit by overfocusing on other metrics like sprint completion.
How to measure it
There are a few different ways to measure capacity utilization. If you’re already doing time logs, then you can look at the amount of time logged against tickets in each sprint and see if it stays at a consistent level or varies a lot, meaning that people are regularly finishing their sprint work in less time.
If you don’t have time logs, you can also look at a spreadsheet showing when each ticket starts and finishes, then add up the gaps to see if there are significant holes.
In minware, you can see the capacity utilization rate in the Focused Dev Time / Work Time chart in the Inspired by Uber's Dashboard report, which compares active dev effort to total number of developers with assigned work. Keep in mind here though that off-sprint work is also counted, so you’ll need to look at under-the-radar work as well to determine if capacity is going toward off-sprint work and underutilized in the sprint itself.
Rollover rate (RR)
Why it’s important
Sprint reports will tell you how many points completed in the current sprint, but they don’t tell you how many of those tickets rolled over from previous sprints.
If a lot of tickets span multiple sprints, that can significantly degrade the value of sprint planning and not be obvious from looking at completed points alone.
I have seen pathological cases where tickets regularly spanned several “sprints” before finally wrapping up.
It’s important to keep an eye on not just throughput, but also total latency/lead time of individual tasks.
How to measure it
To calculate your rollover rate, you can start from the spreadsheet of tickets exported for each sprint. Then, the easiest way to compute rollover is by adding multiple tabs to the same spreadsheet and performing a lookup on each ticket to see if it exists in the tab for the previous sprint.
Alternatively, you can append the tickets for each sprint to a single sheet, and then add a column that sums the number of rows that have the same ticket from higher up in the sheet to arrive at a rollover count, which provides more detailed information than only looking at whether it rolled over from the last sprint.
In either case, you can create a pivot table that shows the total number of points that rolled over vs. the points for tickets that first appeared in the current sprint.
minware’s Sprint Completion Trends report displays the point value of tickets that rolled over once, and separately shows points with >= 2 rollovers so that you can see the rollover rate trend over time.
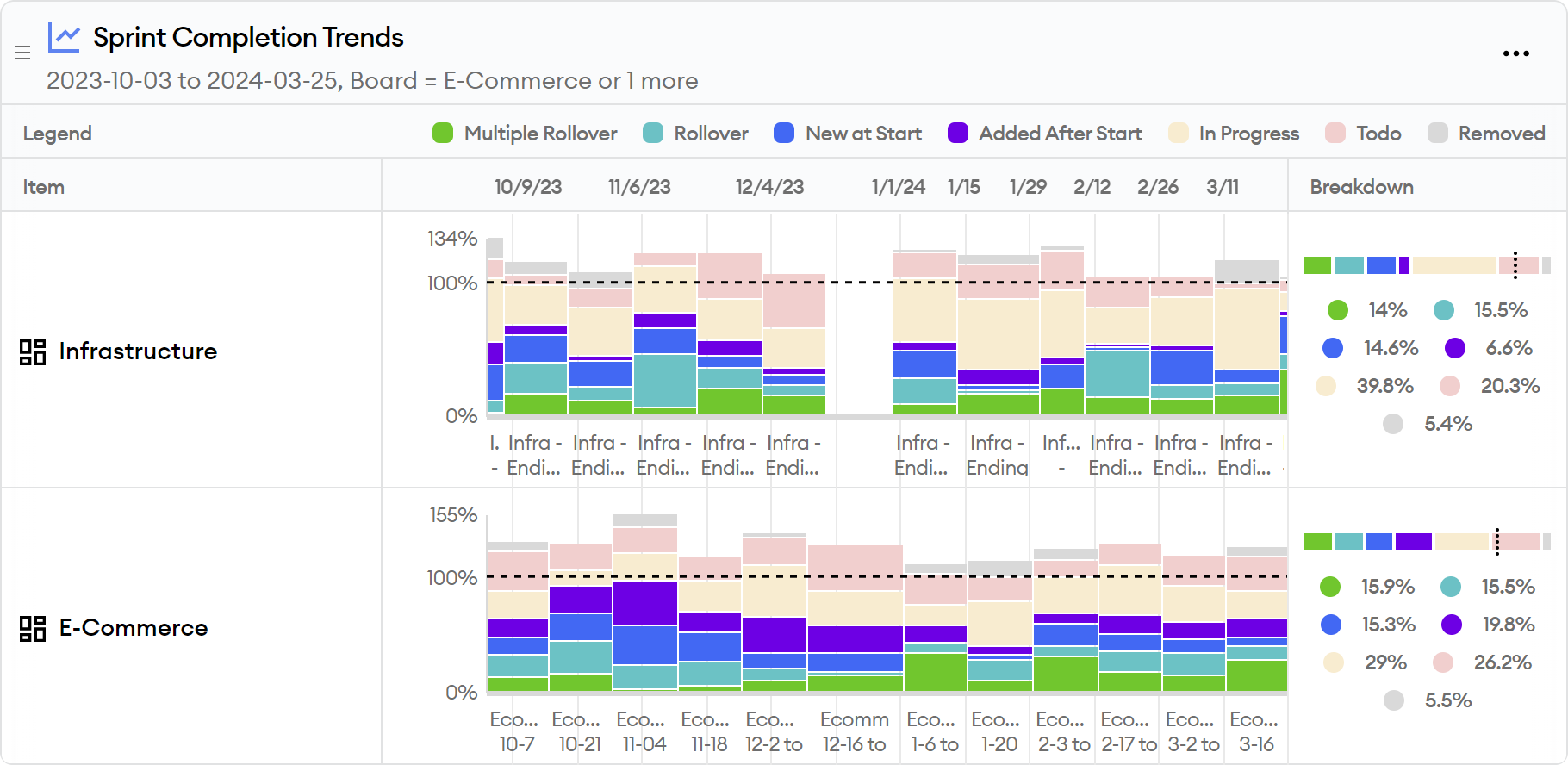
Delivery adjustment rate (DAR)
Why it’s important
An important benefit of sprint planning is that it gives stakeholders an up-to-date picture of when tasks will finish.
However, for this to work, people need to actually remove tasks from the sprint when they add new ones. Otherwise, the sprint plan is meaningless to outsiders and you’re back in the situation of “you’ll know it’s done when it’s done” without the benefits of planning.
If you have a bad sprint and don’t get as much done as planned then that’s one thing, but the delivery adjustment rate looks at how much was added to the sprint without corresponding removals to make sure people are keeping the sprint plan up-to-date.
How to measure it
The delivery adjustment rate is relatively straightforward to compute. You can export a spreadsheet with all the tickets that were in the sprint at the end, sum up their point values, and compare this to the original sprint commitment to see how much the scope expanded minus removed tickets.
The delivery adjustment rate is also easy to see in minware’s Sprint Completion Trends report because removed tickets are broken out in gray and you can see the remaining work compared to the original commitment in the dotted black line.
Scope adjustment rate (SAR)
Why it’s important
Another sprint anti-pattern I’ve seen is removing most of the original tickets and replacing them with new ones.
While some adjustment is good because you don’t want to lock yourself into bad plans if new information emerges, large amounts of scope adjustment can hide poor up-front planning.
By looking at how much effort goes into tickets added after the start of the sprint, you make sure that scope adjustments are truly the result of previously unknown information rather than lax planning.
How to measure it
This one requires a little more manual work to put together. One approach is to look at Jira’s burndown report and tally up all of the scope change rows that increment the scope to arrive at a total scope adjustment. You can then divide the scope adjustment total by the original commitment.
You can see the trend in scope adjustment rate in minware’s Sprint Completion Trends report as well, where completed issues that were added after sprint start are shown in purple along with an overall rate.
Summary
Advanced metrics might sound unnecessary if your team is really lean, but they can provide value for everyone building software.
Calculating the metrics described here isn’t that hard, and can help you get a lot more done with the team you already have.
I have seen small companies with fewer than ten developers compute nearly all of these metrics by hand and still come out way ahead after their time savings.
With systems like minware and others, it’s even easier to get started. Anyone building software today should have strong metrics in place to get the most out of their development processes.
Great stuff! I particularly enjoyed reading your thoughts on UTR and DAR. I think these metrics require both team discipline and personal discipline. If there is a way to measure them, there is a way to show improvement and reward it. Motivation becomes that much more easy to inspire for teams and individuals.
I also liked your idea of reporting on non-bug load. I think that is the correct (positive) perspective on reducing volume of bugs being produced, and therefore being able to focus on new development. Sometimes bug load can be indicative of necessary improvements in some team members more than others. If so, it is my opinion that those improvements are best discussed with those team members in private.
Thanks for another great article!